Reconciliation and Exporting
Reconciliation
OpenRefine has a functionality that should allow user’s to reconcile data with external databases by matching names, subjects or entities to unique identifiers in those databases, standardizing language to specific schemas such as Getty Art & Architecture Thesaurus or Library of Congress Subject Headings.
However, there are complications due to Application Programming Interface (API) compatibility. An API is a set of rules and protocols that allow different software applications to communicate with each other. It acts as a bridge, enabling one application to access the functionality or data of another application in a structured way. Because the reconciliation process engages in a transfer of data, connection failures caused by protection settings can occur, especially with our security parameters as an academic institution.
For example, this is what I encountered trying to reconcile with Getty’s databases and Library of Congress doesn’t even have a listed service in OpenRefine, likely due to a lack of standardized API endpoints needed for this type of integration.
That said, I was able to successfully reconcile with other databases that may be useful for standardization, including Geonames for verifying location names, ORCID iD for bibliometric data and Open Library for general subject terms.
To reconcile data:
- Select the column that you would like to reconcile
- Select the dropdown
Reconcile>Start Reconciling Add Standard Serviceand enter the http address from the Reconciliation Service Test Bench- This will take you to an intermediary screen where you can select which areas of the database you would like to use, select the level of filtering and maximum number of “candidates” to return for each entity
- After a good deal of processing, the candidates will generate in each of the cells and you have the option to select these options for either just the one entity or to apply them to all of the subjects in that column.
✺
Export the Standardized Data
FINALLY
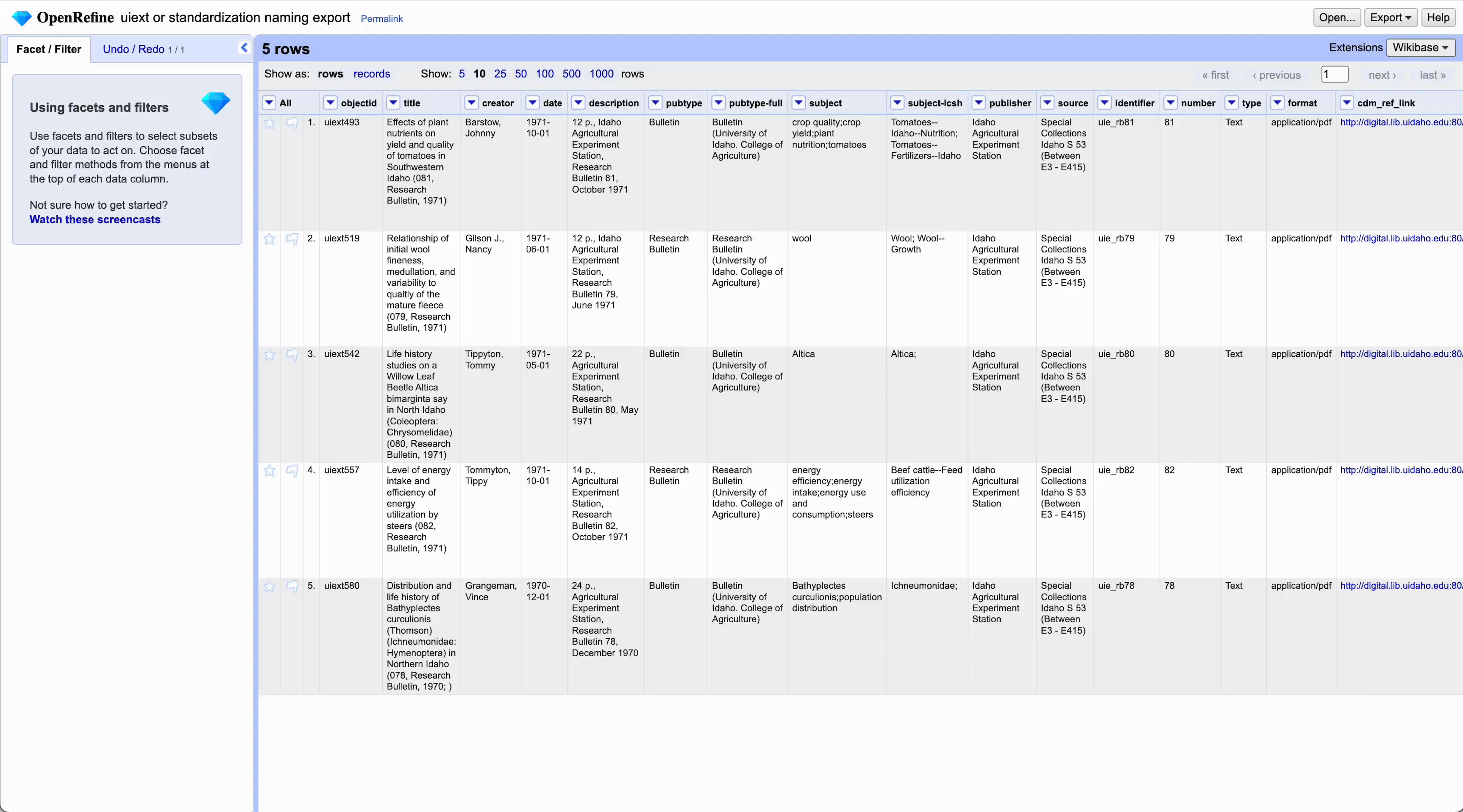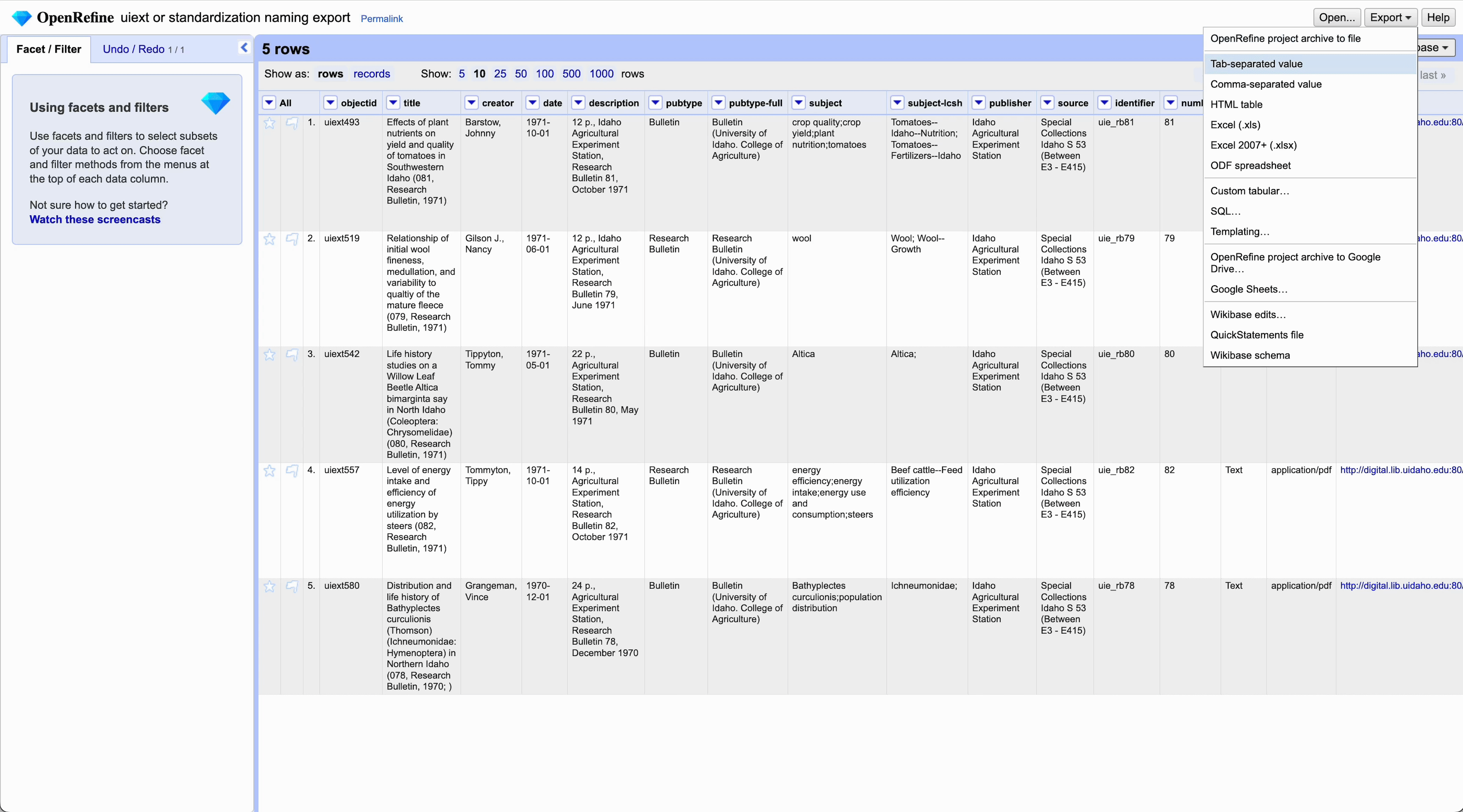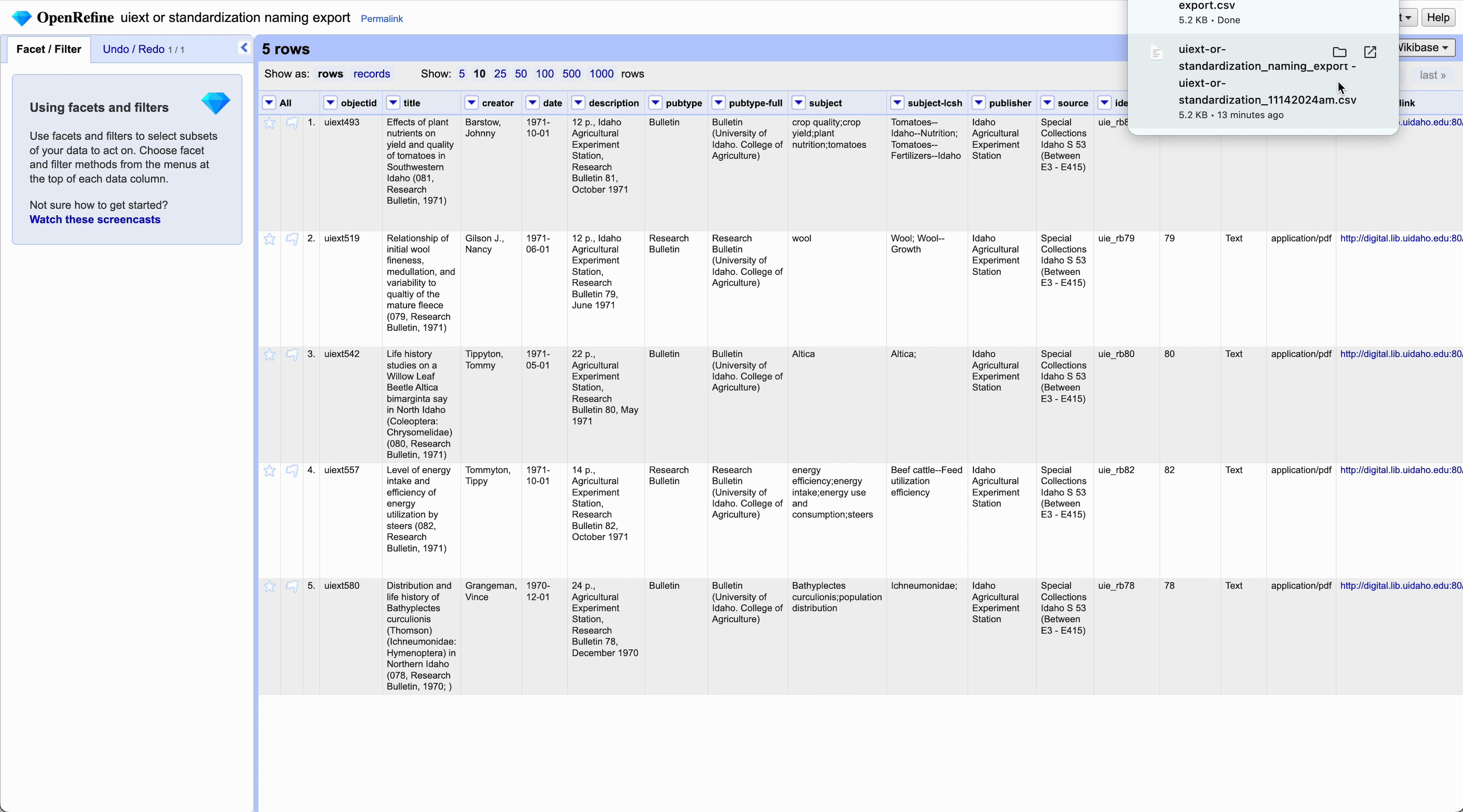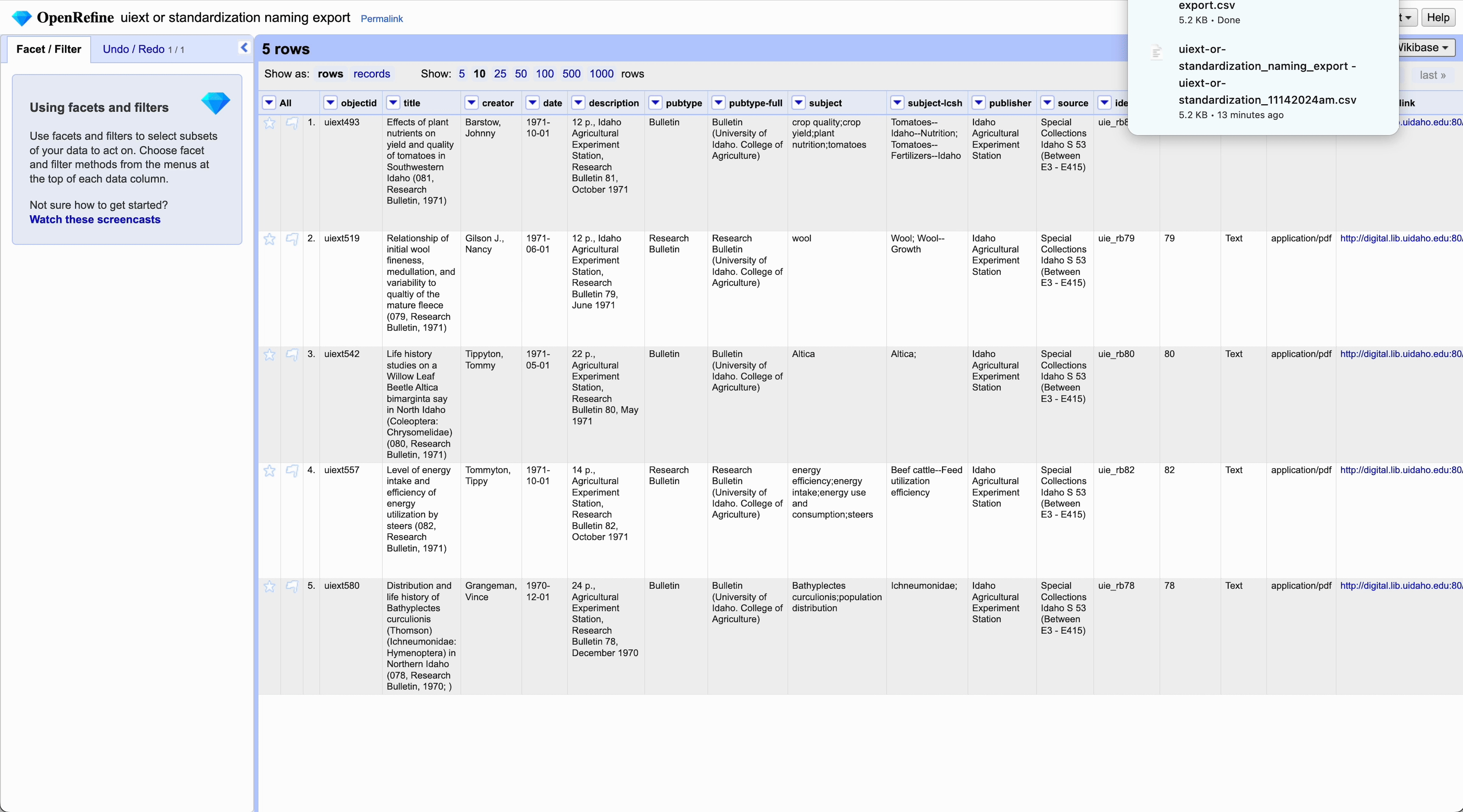
After standardizing, export your project by going to Export > Comma-separated value (CSV)
About the Author: Andrew Weymouth is the Digital Initiatives Librarian at University of Idaho, primarily focusing on static web design to curate the institution’s special collections and partner with faculty and graduate students on fellowship projects. He has also created digital scholarship projects for the universities of Oregon, Washington and the Tacoma Northwest Room archives, ranging from long form audio public history to architectural databases and network visualizations. He writes about labor, architecture, underrepresented communities and using digital scholarship methods to survey equity in archival collections.