Transcription and Tagging
Another challenge of the project was the transcription element. The oral history videos consisted of 15 interviews ranging from an hour and a half to about a half hour. The person conducting the interviews included long pauses and a lot of informal speech, indicating the footage was originally meant to be edited down, but it never was, rendering the material difficult to follow if someone is listening to the recordings linearly. The CDIL’s Oral History as Data or OHD offered a solution in the form of a fully visualized transcription that could be navigated by tagging and keyword searching.
One challenge was that this amount of material would generally take student workers about two semesters to complete with the institution’s previous transcription methods. Building off of my work with the Washington State digital encyclopedia HistoryLink, I experimented with a workflow implementing Adobe Premiere’s transcription tools, which excelled in identifying different speakers, was more accurate than previous tools and could be exported in almost the exact CSV format we needed for OHD. The software also has the advantage of offering a variety of different language packs, which we recently utilized for a Hispanic oral history collection, successfully recognizing speakers frequently jumping between Spanish and English.
✺
Workflow
After testing a few approaches, I was able to find a method that could transcribe an hour and a half long video in around an hour; five minutes to download, ten minutes to process in Premiere, five minutes to format the CSV in Google Sheets and, playing at 2x speed, proof the entire recording for errors in 45 minutes. This proofing and editing can be done ergonomically within Premier’s playback interface or directly into the transcript CSV in Visual Studio Code depending on the severity of the edits needed. In the case of these fifteen videos, which were high fidelity (though featuring some tricky Idaho accents) I’d estimate around a 98% accuracy in Premier’s machine learning.
✺
Tagging Transcripts with Text Mining
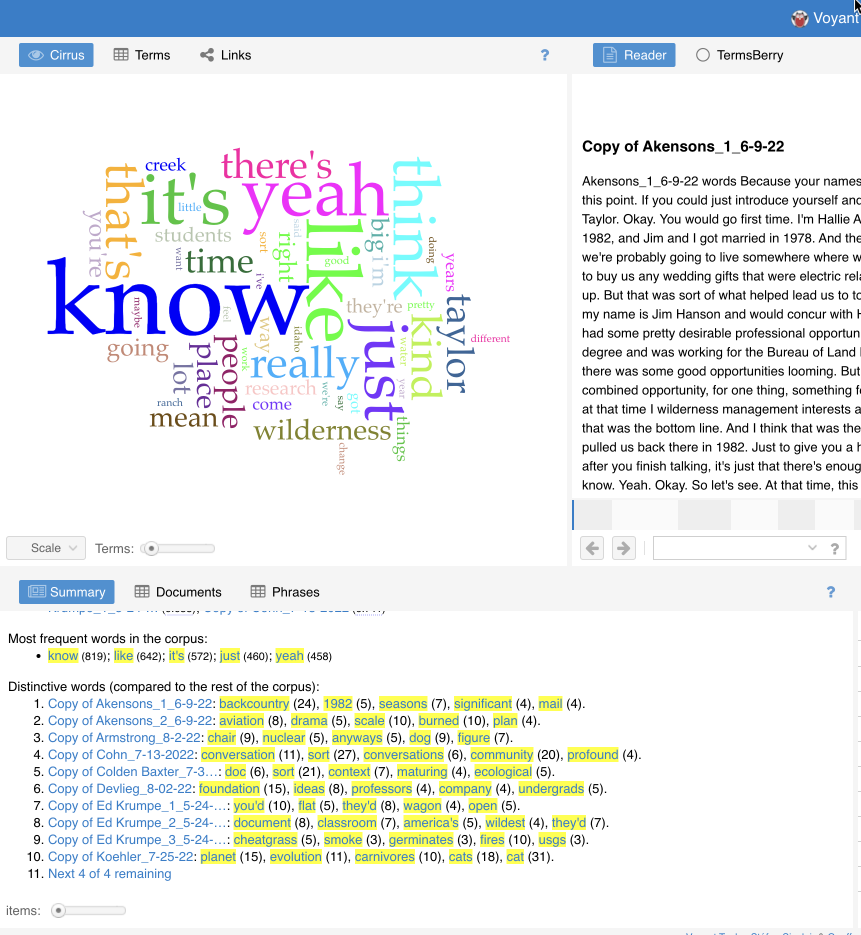
Another strength of OHD is the tagging capability, where threads can be woven through multiple interviews, revealing underlying themes. To efficiently identify tag material, I dropped all of the transcript CSVs into the freely available text mining engine Voyant.

Normally, this type of text mining analysis would require some amount of “cleaning” to remove all of the filler words from a document, but pulling from the “distinctive words” section of the summary can provide a similar snapshot. Copying this data from all fifteen transcriptions, I identified repeating themes, created a synonym list for those tags, searched each document for these words, and added the appropriate tag into the column next to where that dialogue appears in the transcript CSV.
Since working on this project, I’ve developed this process, moving away from Voyant and building a text mining tool from scratch using Python with results I’m excited to write about and expand on in future work.
✺