Process
Contents: Overview | Transcription | Python Text Mining | Apps Script Connection and Customization
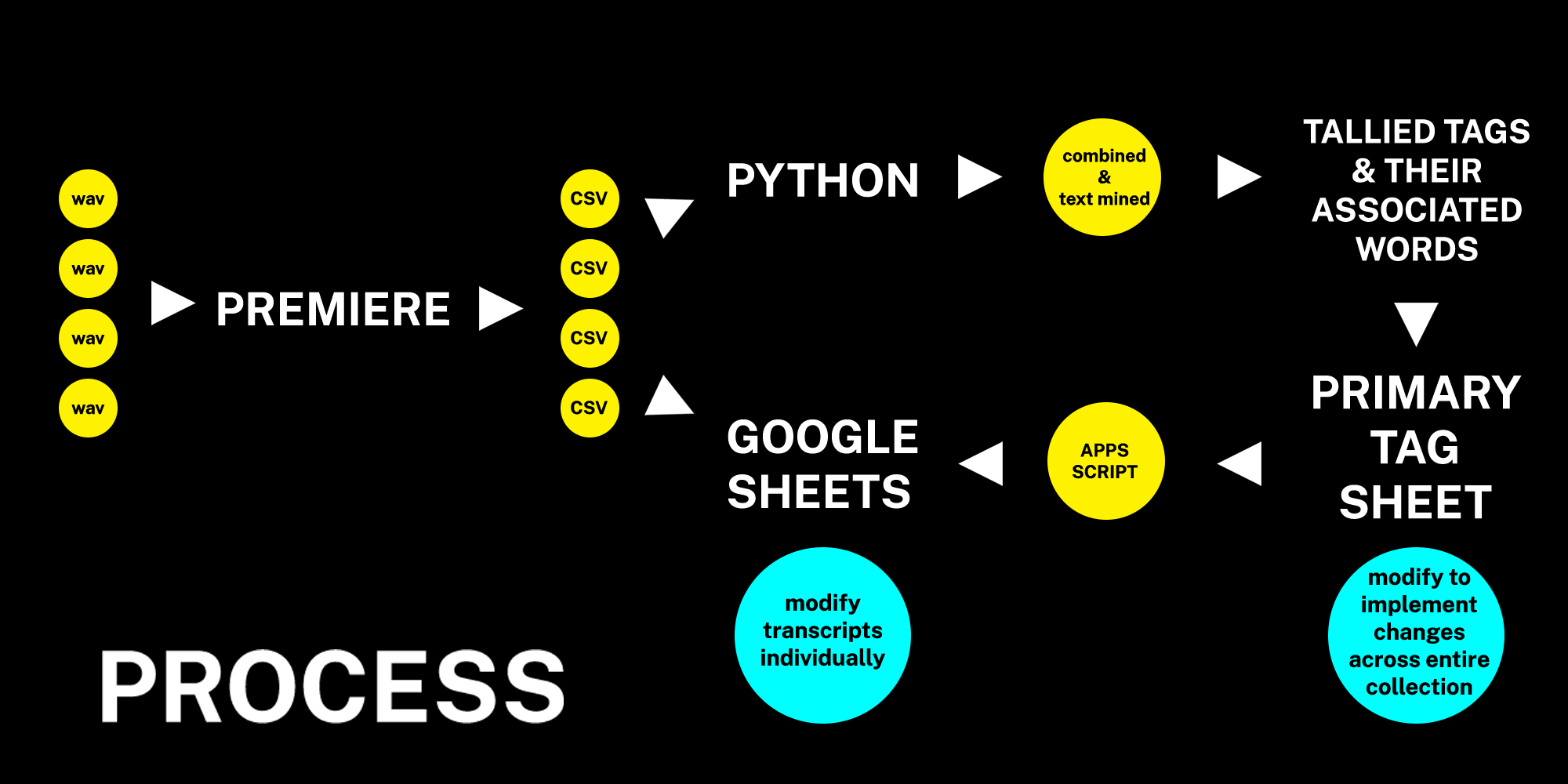
Overview
To summarize the process:
-
Audio is transcribed into CSV files by Premiere
-
CSVs are made into individual Google Sheets and also added to the Python Transcription Mining Tool
-
Within the tool, these items are combined and searched for all associated words and phrases built into the tool under different tag categories
-
The tool generates a tally of the these words and phrases, which is used to create the “Primary Tag Sheet” in another Google Sheet
-
Using the Apps Script function, all individual transcripts are linked to the primary tag sheet so their tag fields are automatically generated
-
New categories or associated words can be added or removed to the Primary Tag Sheet and these changes can be implemented across all individual transcripts by simply re-running the code
-
Individual changes can be implemented during the student worker led copy editing process to catch any data driven errors
✺
Transcription
Moving away from the speech to text tools the department had been working with, I tested Adobe Premiere’s transcription tools and found it uniquely well-suited for the OHD framework, with advantages including:
-
Dramatically increased accuracy in differentiating speakers and transcribing dialogue, even with obscure and regional proper nouns.
-
Significantly faster transcription speed, from one 1.5-hour recording every two to three business days up to twenty 1.5-hour recordings in one day.
-
Costs covered by our university-wide Adobe subscription.
-
Direct export to CSV UTF-8 needed for OHD, avoiding conversion errors.
-
Free non-English language packs, enabling the creation of the department’s first Spanish and French language oral history collections.
-
Privacy standards with Premiere’s GDPR compliance, ensuring all transcription material is stored locally and not uploaded to the cloud.[2]

That said, the tool is not perfect. While modern recordings in good conditions have extremely high transcription accuracy, poor quality recordings and interviews between two similar sounding people can require significant copyediting. Recent work by Matt Miller of the Library of Congress has me very interested in creating custom speech to text tools using Whisper(.cpp) to possibly help improve on these inaccuracies.[3]
While some negative perspectives of speech to text tools have to do with bias built into machine learning (Link, 2020), others stem from academic double standards expecting written transcripts to be an improved version of the audio rather than a reflection of it. Some of these notions may have origins in the earliest American academic oral history transcription standards of Columbia University, where editors were encouraged to delete “false starts”, audit wording, rearrange passages into topical or chronological order or delete whole sections to transform the transcript from “what might be dismissed as hearsay into a document that has much the standing of legal disposition”, essentially divorcing the transcript from the audio.(Freund, 2024)
Since then, critics of this practice of “cleaning up” oral history transcripts have emerged, pointing out how it introduces unnecessary editorial bias. As University of Kentucky’s Susan Emily Allen notes in Resisting the Editorial Ego: Editing Oral History:
"These texts take it upon themselves to glean 'what words are meaningful.' Meaningful for whom? For the editor? Such subjectivism is not only rather irresponsible scholarship but, however well-intentioned, an attempt to legislate truth." (Allen, 1982)
✺
Python Text Mining
After using the web based text mining tool Voyant while developing subject tags for the Taylor Wilderness Research Station digital collection, I wanted to create a text mining tool from scratch using Python. This would allow the targeting of specific words and phrases, create custom tagging categories and “stopwords” (words removed from text before processing and analysis) for each collection.
Once the CSVs of the transcript are added to a folder in the Python workspace, the code begins with importing Pandas library for data manipulation, the Natural Language Toolkit and TextBlob for language processing and sentiment analysis. Additionally, Regular Expressions and the ‘collections.Counter’ function are added for text mining and tallying results.
Next, the ‘preprocess_text’ function removes words of four characters or fewer, eliminates punctuation, and converts all text to lowercase. CSV file paths are constructed, and the text data is concatenated into a single string corpus. Stopwords are removed, word frequency is counted and the 100 most frequent words and phrases are generated when the code is run.
Below this header material in the Python file are three text mining categories:
-
General: agriculture, animals, clothing, etc.
-
Geographic (based loosely on migration statistics from the 1910 Idaho census[3]): britain, canada, china, etc.
-
Custom (example from our Rural Women’s History Project): Marriage and Divorce, Motherhood, Reproductive Rights, etc.
Each of these sections have a list of fifty associated words and phrases that the script is searching for within the combined transcription corpus. These were generated using Chatgpt with the following qualifications:
-
The word or phrase is only associated with one section. For example, regarding the sections agriculture and animals, the word “pasture” would be excluded since it could refer to both the land used for grazing animals and also the act of animals grazing.
-
Exclude homographs (words that are spelled the same but have different meanings). For example, sow refers both to an adult female pig and the agricultural act of planting seeds in the ground.
-
Place names and how certain nationalities would refer to themselves for the geographic sections. For example, “Philippines”, “Filipino”, “Tagalog…”, “Norwegian”, “Norway”, “Oslo…” or “Japanese”, “Japan”, “Tokyo”, etc.
These text mining categories and sections produce a total of 2,250 associated words phrases that are being identified across the combined transcript corpus before the script tallies these words to generate the output shown below:

Future iterations of this repository will modularize the General, Geographic and Custom sections for easier navigation instead of its current form as a single, expansive Python file. See Appendix 1 for an excerpt of this script or visit the GitHub repository to view code in full.
Apps Script Connection and Customization
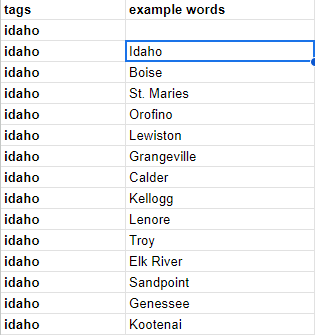
Once this text mining data is produced, it can be copied and pasted into a “primary tag sheet” in Google Sheets, located in the same folder as the transcripts for student workers to access and edit. Using the Text to Columns function, tag names are split into column A and their associated words into column B.
After making some minor adjustments to the individual transcript that has been generated using Premiere necessary for the Oral History as Data framework, student workers access the Apps Script extension located in the drop down menu. Transcribers then enter the code (see Appendix 2), and make two minor adjustments:
-
Change the sheet name of the transcript they are editing on line 6
-
Change the URL of their primary tag sheet on line 13, then save and run the code.
Now the individual transcript is connected to the Primary Tag Sheet, which will automatically search the text column for these associated words and fill in the tag column of the transcript with that data.
✺
It’s important to state that this process is not intended to replace human transcribers but shifts the focus from manual tagging to copy editing, reducing heavy lifting and repetition.
If transcribers notice that a tag is either not applicable or missing from the Primary Tag Sheet, they are encouraged to make these additions or subtractions and rerun the Apps Script on their individual transcripts, which will automatically make these adjustments. If transcribers notice errors that are more specific to individual sections of dialogue, they can paste it into the additions or subtractions column so these changes aren’t replaced by future runs of the Apps Script and reflected in the final copyedited version that is implemented in the digital collection.