Findings
While testing this process with two transcribers over the summer of 2024, two of my main concerns were:
- Would they find the Apps Script coding element confusing and/or anxiety-inducing?
- Would the automated tagging generate a lot of inappropriate tags that would make correcting these items a drag on productivity?
At least with this small sample group, these factors weren’t an issue. Possibly helpful in this effort was weekly meetings where we checked in and tested the code, sometimes purposefully breaking it to show how those mistakes can be easily fixed and demonstrate how they can update the Primary Tags Sheet and rerun the code on their individual transcript sheets. Rather than simply asking student workers to transcribe recordings—work that offers little to highlight on a CV and can lead to burnout and high turnover—this process allows transcribers to engage in coding, create and modify tags, and see those changes reflected instantly through the Apps Script process.
In addition to helping us meet our department’s accessibility standards, this process enabled us to complete our first non-English oral history collection in the form of the Hispanic Oral History Project, an initiative from 1991 copyedited by student worker Daniel Olortegui Vargas. This work in progress will be using this material to enhance the OHD item-level interface, allowing listeners to toggle between English and Non-English transcriptions. This new feature in the open-source OHD framework aims to promote the digitization of more diverse oral history collections both within and beyond the institution.
From what I can gather, this approach has generated a significant increase in both the volume, accuracy and detail of oral history transcription work from the previous summer’s efforts. In addition to the tools discussed in this article, other factors contributing to this progress include:
- A more dynamic, interactive workflow leading to greater transcriber productivity
- Less repetitive labeling and formatting work hopefully leading to increased output and student worker retention
- Supplementary documentation helping transcribers navigate the more technical aspects of the workflow
- All tags use a controlled vocabulary necessary for the OHD framework
- Tagging is more accurate, detailed, and relevant, helping future researchers quickly identify thematic connections
- Text mining tool establishes a knowledge framework relevant to the collection that transcribers may lack in historical, scientific, or regional contexts key to the recordings
✺
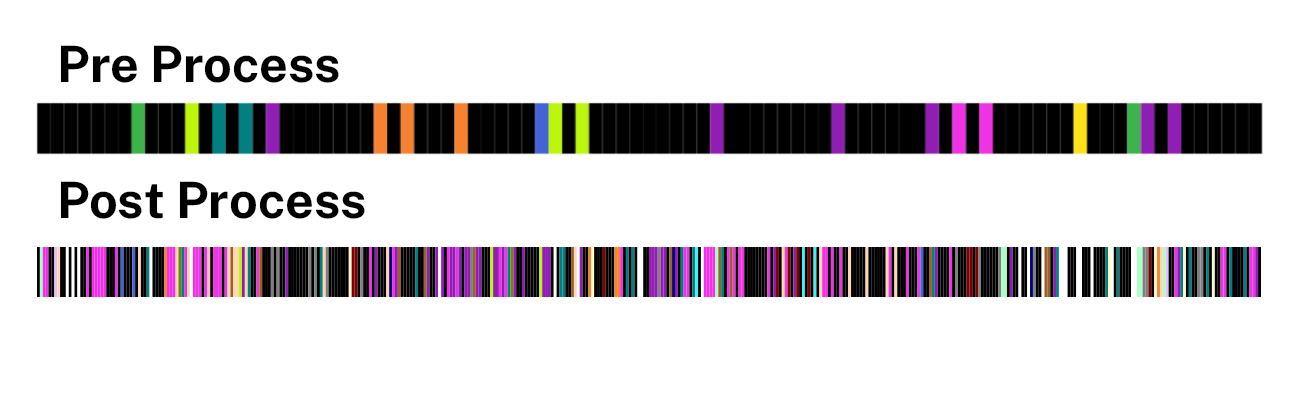
Regarding the limitations of data-driven, human-edited automated tagging, program managers must communicate that automated tags are only a starting point. Tags may be incorrectly applied, missing or need to be applied more broadly to transcripts. Even when these measures are taken, the amount of detail this process accrues is drastic and easily distinguishable in the OHD tagging visualization (fig. 1). One could argue that the density of the data now makes it difficult for the researcher to navigate, especially on mobile devices. This continues to be a dialogue as we refine these processes.
✺
Conclusion
While discussing grant funding for digital initiatives, a colleague pointed out that the time-intensive nature of oral history projects often leads to their neglect. As they put it:
“Would you rather present ten oral history recordings or 500 photographs?”
This quantity-focused selection criteria ultimately poses an existential threat, leaving these materials physically vulnerable as they languish in the archives. Bicentennial and community oral history initiatives, rich in non-academic perspective, offer a uniquely biographical account of places and provide valuable contrast and context to the accepted historical record. By utilizing machine learning, Python, and JavaScript approaches, this process seeks to make digitizing these resources more efficient and accessible, promoting their preservation and availability to the public.