Introduction
Hello, my name is Andrew Weymouth and I work at the University of Idaho Library as the Digital Initiatives Librarian in the Center for Digital Inquiry and Learning (CDIL) department. My work generally consists of creating and maintaining our digital collections, helping to rethink processes and introducing new digital scholarship tools to the department.
Why?
This workflow was prompted by pursuing an MA in History with University of Idaho in the fall of 2024 while also working as a faculty member with the library. I wanted to develop a note taking system that could visualize connections across all of the literature I am reading to create historiographies specifically, but would also be helpful in conducting the literature reviews, data collection and environmental scans that I need to do to create scholarly work for my position. Beyond the discipline of history, Obsidian is also a very popular knowledge organization tool for scholars working in computer and data science, mathematics, physics, biology and medicine.
I was initially inspired to pursue Obsidian by a Tech Talk I attended last year from interdisciplinary botany PhD Student and previous CDIL Fellowship recipient Nick Koenig. The presentation centered on using Obsidian for research and they mentioned that there were community plug-ins that were developed to connect Zotero to the platform. After testing out these tools, I wanted to find out if there was a more reliable and customizable solution for connecting these two platforms that not only extracted annotated material but one which also categorized annotations according to highlight color.
✺
Zotero
Zotero is an open source reference management software developed by the Roy Rosenzweig Center for History and New Media at George Mason University in 2006. Since jumping from an internal academic tool to incorporation in 2013, the software has gained widespread adoption by writers, students and researchers as a more versatile and digital preservation focused alternative to other citation managers like EndNote and Mendeley.

Zotero excels as a temporary processing area, where you can drop all of your research, easily record websites using their browser plug-in, annotate in your preferred word processor and then export in a lightweight file that can be opened again in Zotero whenever you need it. Also, unlike Obsidian, it is very convenient to collaboratively engage with reading material in shared libraries, which is helpful for conducting group literature reviews.
✺
Obsidian
Obsidian was founded in 2020 as a markdown file based knowledge management tool that has a very active user base and regularly updates systems based on that feedback. Obsidian supports the use of multiple computer languages, including JavaScript, HTML and CSS to style and format your text but, as we will see later, you can do as much or as little coding as you are interested in.
Obsidian workspaces are called vaults which are essentially just folders of markdown files. How you choose to structure the folders within your vault allows you to highlight and visualize your research, which we will explore in greater detail further along in this workshop.
Unlike cloud-based note taking apps, Obsidian is designed to be fully functional on your local device, not even requiring an internet connection, which is key if you are working on research projects with sensitive data. While Obsidian has a subscription cloud based version called Sync and Publish, this workshop will show you how to host your site on a free cloud storage platform such as Google Drive or Microsoft OneDrive so you can sync your vaults between devices at no additional cost.
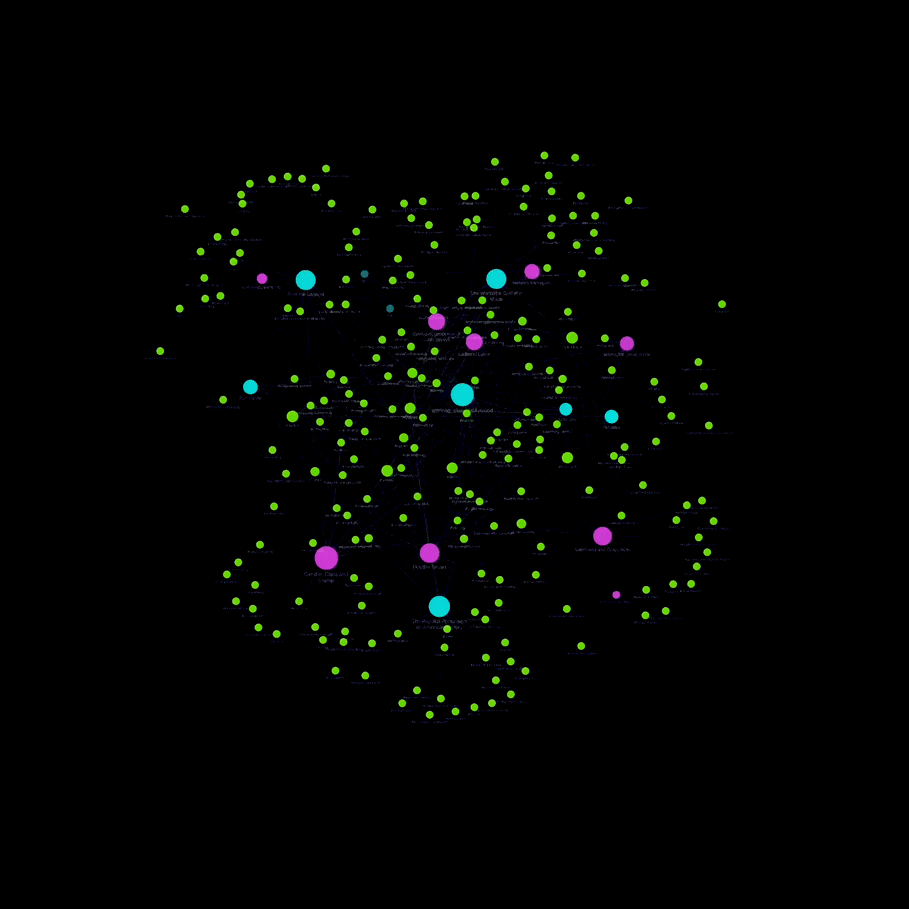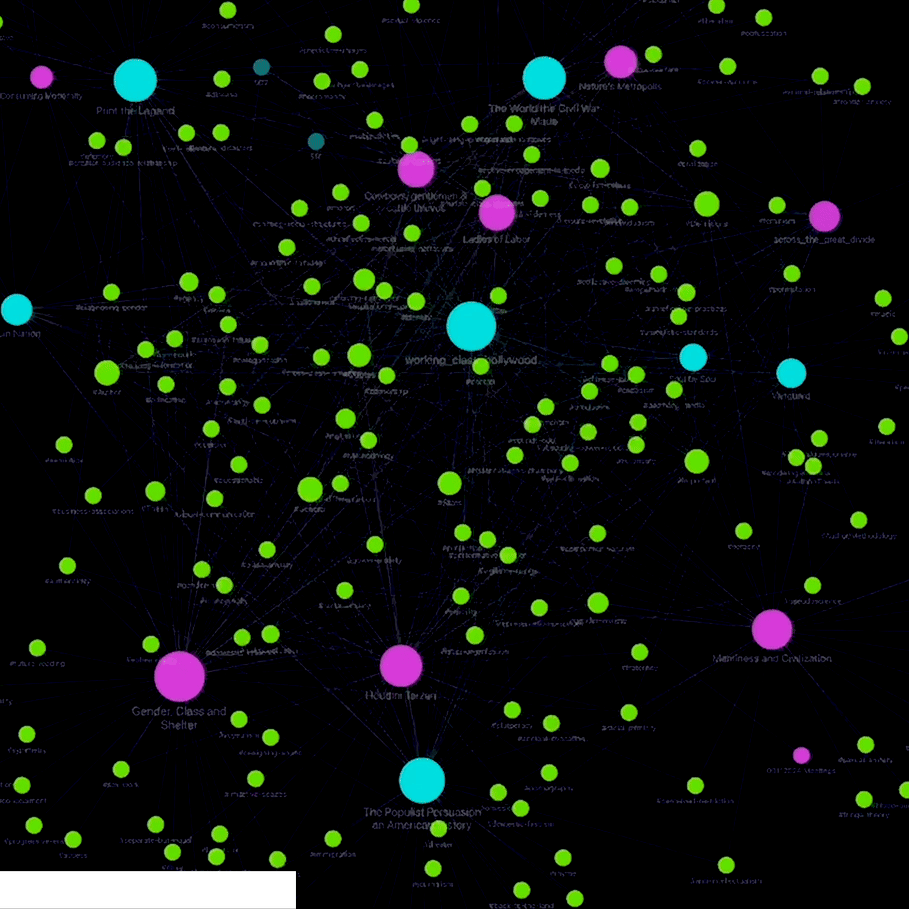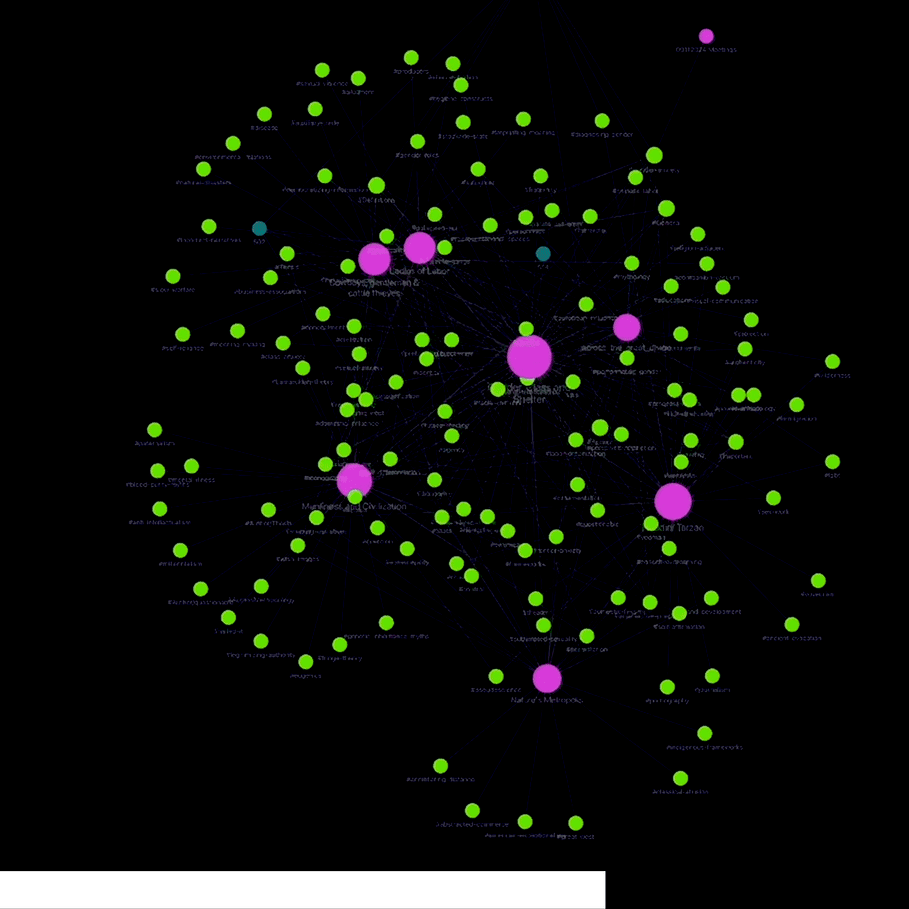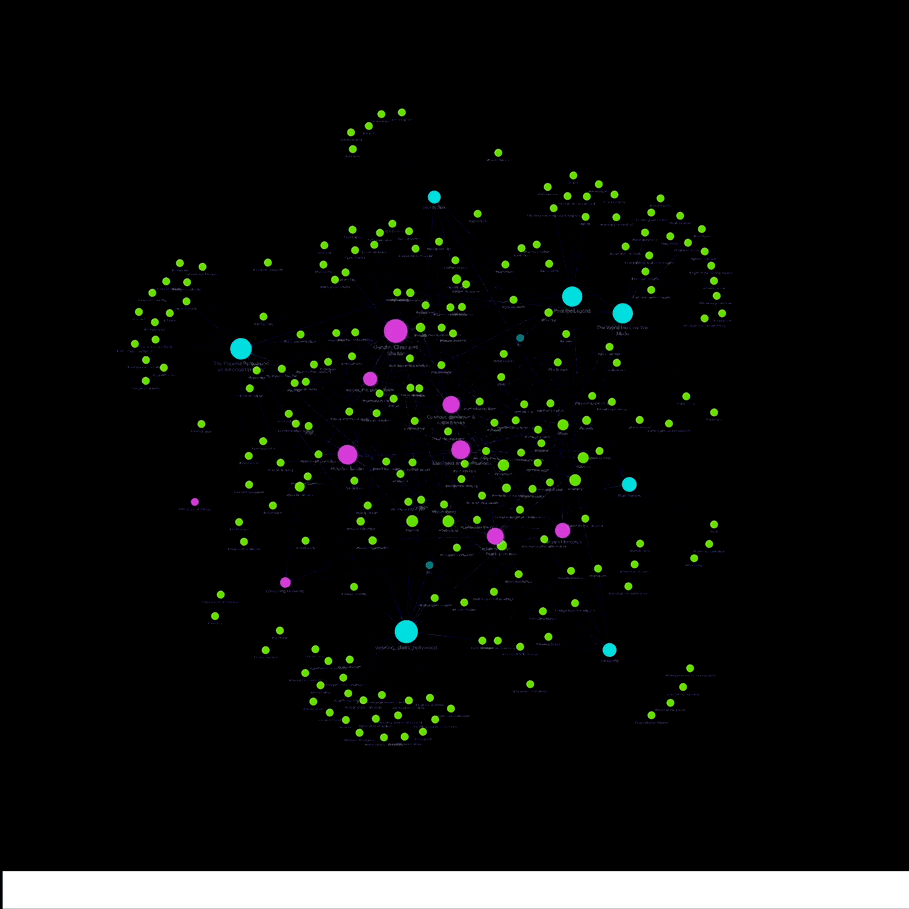
Obsidian’s key strength is it’s ability to link notes, tags and subtags together, creating an interconnected “web of knowledge”. The built-in graph view allows researchers to interact with a visual representation of these connections, which can be helpful in understanding overarching themes and relationships between large amounts of text rather than simply filtering by keyword searches. Additionally, I find that the process of creating tags and thinking about the ways they may or may not apply to different subject matter is a uniquely proactive, creative process that allows researchers to understand the material in new ways.
✺